
Kubernetes部署AlertManager
系统环境
- 操作系统: CentOS 7.6
- Docker 版本: 19.03.5
- Prometheus 版本: 2.36.0
- Kubernetes 版本: 1.20.0
- AlertManager 版本: 0.24.0
AlertManager简介
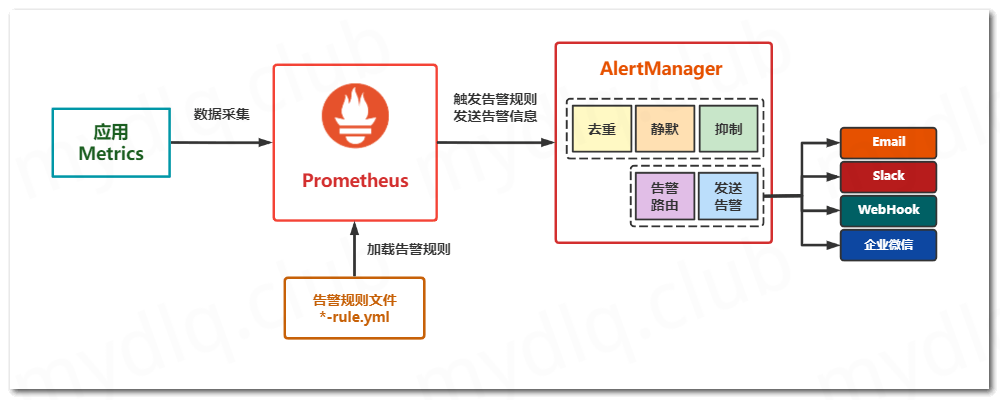
AlertManager是一个专门用于实现告警的工具,可以实现接收Prometheus或其它应用发出的告警信息,并且可以对这些告警信息进行分组、抑制以及静默等操作,然后通过路由的方式,根据不同的告警规则配置,分发到不同的告警路由策略中。除此之外,AlertManager还支持 “邮件”、“企业微信”、“Slack”、“WebHook” 等多种方式发送告警信息,并且其中 WebHook 这种方式可以将告警信息转发到我们自定义的应用中,使我们可以对告警信息进行处理,所以使用 AlertManager 进行告警,非常方便灵活、简单易用
AlertManager 常用的功能主要有:
抑制: 抑制是一种机制,指的是当某一告警信息发送后,可以停止由此告警引发的其它告警,避免相同的告警信息重复发送。
静默: 静默也是一种机制,指的是依据设置的标签,对告警行为进行静默处理。如果 AlertManager 接收到的告警符合静默配置,则 Alertmanager 就不会发送该告警通知。
发送告警: 支持配置多种告警规则,可以根据不同的路由配置,采用不同的告警方式发送告警通知。
告警分组: 分组机制可以将详细的告警信息合并成一个通知。在某些情况下,如系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警信息合并为一个告警通知,从而避免一次性发送大量且属于相同问题的告警,导致无法对问题进行快速定位。其中 Prometheus 和 AlertManager 的关系如下图所示:
创建AlertManager存储PVC
在部署AlertManager之前创建一下用于存储AlertManager数据的PVC资源文 alertmanager-storage.yaml
[root@k8s01 alertmanager]# vim alertmanager-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager-pvc
namespace: monitoring
labels:
app: prometheus
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
storageClassName: managed-nfs-storage
[root@k8s01 alertmanager]# kubectl apply -f alertmanager-pvc.yaml
persistentvolumeclaim/alertmanager-pvc created
创建AlertManager配置文件ConfigMap
创建AlertManager配置文件alertmanager-config.yaml
[root@k8s01 alertmanager]# vim alertmanager-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: monitoring
data:
alertmanager.yml: |-
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.exmail.qq.com:25'
smtp_from: 'xxxxxxxxxxxx'
smtp_auth_username: 'xxxxxxxxxxxx'
smtp_auth_password: 'asdASD123'
smtp_require_tls: false
templates:
- '/etc/alertmanager/*.tmpl'
route:
group_by: ['env','instance','type','group','job','alertname','cluster']
group_wait: 10s
group_interval: 2m
repeat_interval: 10m
receiver: 'email'
routes:
- receiver: 'wechat'
match:
severity: error
receivers:
- name: 'email'
email_configs:
- to: 'xxxxxxxxxxxx'
send_resolved: true
html: '{{ template "email.to.html" . }}'
- name: 'wechat'
wechat_configs:
- corp_id: xxxxxxxxxxxx
to_user: '@all'
agent_id: xxxxxxxxxxxx
api_secret: xxxxxxxxxxxx
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
wechat.tmpl: |-
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 告警恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
email.tmpl: |-
{{ define "email.from" }}xxx.com{{ end }}
{{ define "email.to" }}xxx.com{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{ range .Alerts }}
========= 监控报警 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{ range .Alerts }}
========= 告警恢复 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- end }}
[root@k8s01 alertmanager]# kubectl apply -f alertmanager-config.yaml
configmap/alertmanager-config created
参数说明:
global:
resolve_timeout: 5m ##超时,默认5min
smtp_smarthost: 'smtp.exmail.qq.com:25'
smtp_from: 'xxxxxxx'
smtp_auth_username: 'xxxx'
smtp_auth_password: '123'
smtp_require_tls: false
smtp_hello: 'x.com' #alertmanager地址
templates: ##告警模板(可定义多个)
- '/etc/alertmanager/*.tmpl'
##route:用来设置报警的分发策略。Prometheus的告警先是到达alertmanager的根路由(route),alertmanager的根路由不能包含任何匹配项,因为根路由是所有告警的入口点
##另外,根路由需要配置一个接收器(receiver),用来处理那些没有匹配到任何子路由的告警(如果没有配置子路由,则全部由根路由发送告警),即缺省
##接收器。告警进入到根route后开始遍历子route节点,如果匹配到,则将告警发送到该子route定义的receiver中,然后就停止匹配了。因为在route中
##continue默认为false,如果continue为true,则告警会继续进行后续子route匹配。如果当前告警仍匹配不到任何的子route,则该告警将从其上一级(
##匹配)route或者根route发出(按最后匹配到的规则发出邮件)。查看你的告警路由树,https://www.prometheus.io/webtools/alerting/routing-tree-editor/,
##将alertmanager.yml配置文件复制到对话框,然后点击"Draw Routing Tree"
route:
group_by: ['env','instance','type','group','job','alertname','cluster'] ##用于分组聚合,对告警通知按标签(label)进行分组,将具有相同标签或相同告警名称(alertname)的告警通知聚合在一个组,然后作为一个通知发送。如果想完全禁用聚合,可以设置为group_by: [...]
group_wait: 10s ##当一个新的告警组被创建时,需要等待'group_wait'后才发送初始通知。这样可以确保在发送等待前能聚合更多具有相同标签的告警,最后合并为一个通知发送
group_interval: 2m ##当第一次告警通知发出后,在新的评估周期内又收到了该分组最新的告警,则需等待'group_interval'时间后,开始发送为该组触发的新告警,可以简单理解为,group就相当于一个通道(channel)
repeat_interval: 10m ##告警通知成功发送后,若问题一直未恢复,需再次重复发送的间隔(根据实际情况来调整)
receiver: 'email' ##配置告警消息接收者,与下面配置的对应,例如常用的 email、wechat、slack、webhook 等消息通知方式。
routes: ##子路由
- receiver: 'wechat'
match: ##通过标签去匹配这次告警是否符合这个路由节点;也可以使用match_re进行正则匹配
severity: error ##标签severity为error时满足条件使用wechat警报
continue: true ##匹配到这个路由后是否继续匹配,默认flase
receivers: ##配置报警信息接收者信息
- name: 'email' ##警报接收者名称
email_configs:
- to: 'xxxxxx' ##接收警报的email(可引用模板文件中定义的变量),可定义多个
## html: '{{ template "email.to.html" .}}' ##发送邮件的内容(调用模板文件中的)
helo: 'alertmanager.com' #alertmanager的地址
send_resolved: true #故障恢复后通知
- name: 'wechat'
wechat_configs:
- corp_id: xxxxxxxxx ##企业信息
to_user: '@all' ##发送给企业微信用户的ID,这里是所有人
agent_id: xxxxx ##企业微信AgentId
api_secret: xxxxxxxxx ##企业微信Secret
## message: '{{ template "wechat.default.message" .}}' ##发送内容(调用模板里面的微信模板)
send_resolved: true ##故障恢复后通知
inhibit_rules: ##抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
k8s部署AlertManager
部署AlertManager
创建AlertManager部署文件alertmanager-deploy.yaml
[root@k8s01 alertmanager]# vim alertmanager-deploy.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: monitoring
labels:
k8s-app: alertmanager
spec:
type: NodePort
ports:
- name: http
port: 9093
targetPort: 9093
nodePort: 30093
selector:
k8s-app: alertmanager
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitoring
labels:
k8s-app: alertmanager
spec:
replicas: 1
selector:
matchLabels:
k8s-app: alertmanager
template:
metadata:
labels:
k8s-app: alertmanager
spec:
containers:
- name: alertmanager
image: prom/alertmanager:v0.24.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 9093
args:
## 指定容器中AlertManager配置文件存放地址 (Docker容器中的绝对位置)
- "--config.file=/etc/alertmanager/alertmanager.yml"
## 指定AlertManager管理界面地址,用于在发生的告警信息中,附加AlertManager告警信息页面地址
- "--web.external-url=https://alertmanager.x.com"
## 指定监听的地址及端口
- '--cluster.advertise-address=0.0.0.0:9093'
## 指定数据存储位置 (Docker容器中的绝对位置)
- "--storage.path=/alertmanager"
resources:
limits:
cpu: 1000m
memory: 512Mi
requests:
cpu: 1000m
memory: 512Mi
readinessProbe:
httpGet:
path: /-/ready
port: 9093
initialDelaySeconds: 5
timeoutSeconds: 10
livenessProbe:
httpGet:
path: /-/healthy
port: 9093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: data
mountPath: /alertmanager
- name: config
mountPath: /etc/alertmanager
- name: configmap-reload
image: jimmidyson/configmap-reload:v0.7.1
args:
- "--volume-dir=/etc/config"
- "--webhook-url=http://localhost:9093/-/reload"
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/config
readOnly: true
volumes:
- name: data
persistentVolumeClaim:
claimName: alertmanager-pvc
- name: config
configMap:
name: alertmanager-config
[root@k8s01 alertmanager]# kubectl apply -f alertmanager-deploy.yaml
service/alertmanager created
deployment.apps/alertmanager created
访问AlertManager管理界面
Prometheus添加告警配置
Prometheus配置AlertManager告警规则
由于已经通过k8s部署prometheus并使用了ConfigMap资源存储Prometheus配置文件,所以需要对Prometheus配置文件进行改动,就需要修改ConfigMap资源文件prometheus-config.yaml,改动内容如下:
- 添加AlertManager服务器地址
- 指定告警规则文件路径位置
- 添加Prometheus中触发告警的告警规则
[root@k8s01 prometheus]# vim prometheus-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
cluster: "kubernetes"
############ 添加配置 Aertmanager 服务器地址 ###################
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:9093"]
############ 指定告警规则文件路径位置 ###################
rule_files:
- /etc/prometheus/*-rule.yml
...
## 新增告警规则文件,可以参考: https://prometheus.io/docs/alerting/latest/notification_examples/
test-rule.yml: |
groups:
- name: Instances
rules:
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.'
summary: 'Instance {{ $labels.instance }} down'
[root@k8s01 prometheus]# kubectl apply -f prometheus-config.yaml
configmap/prometheus-config configured
重新加载新的配置
[root@k8s01 prometheus]# kubectl delete -n monitoring pod prometheus-0 prometheus-1
Prometheus UI查看配置和告警规则是否生效
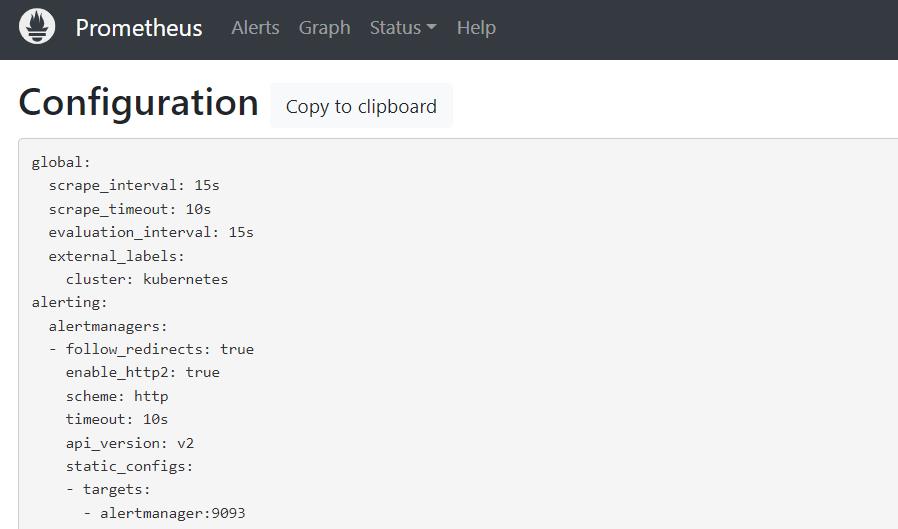
配置文件 (Configuration界面)
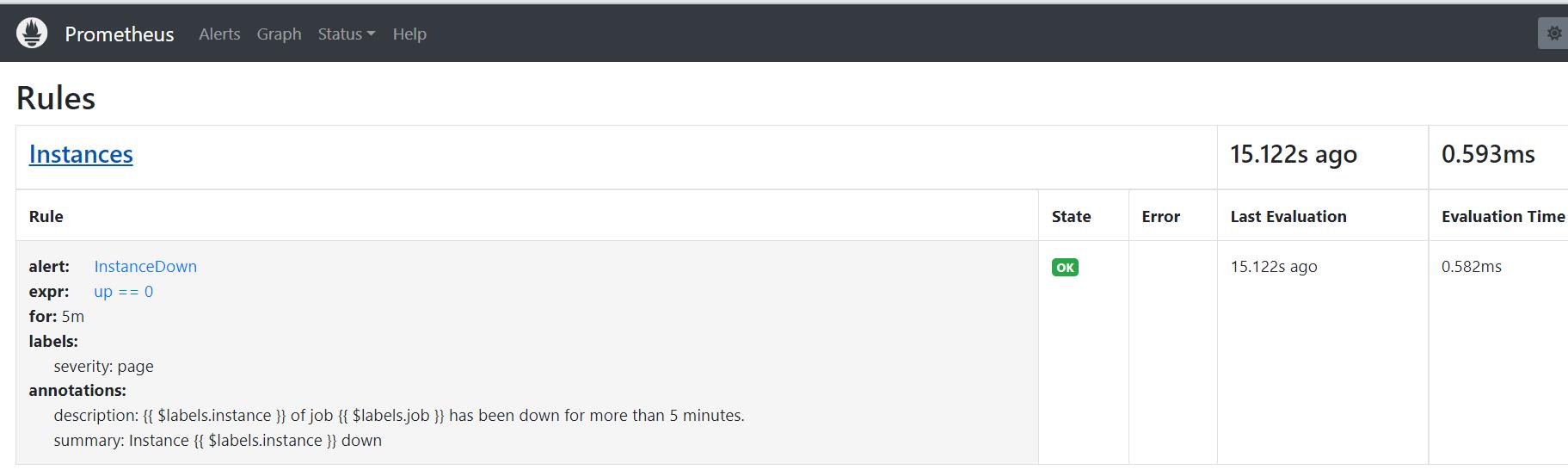
告警规则 (Rules界面)
告警状态 (Alerts界面)
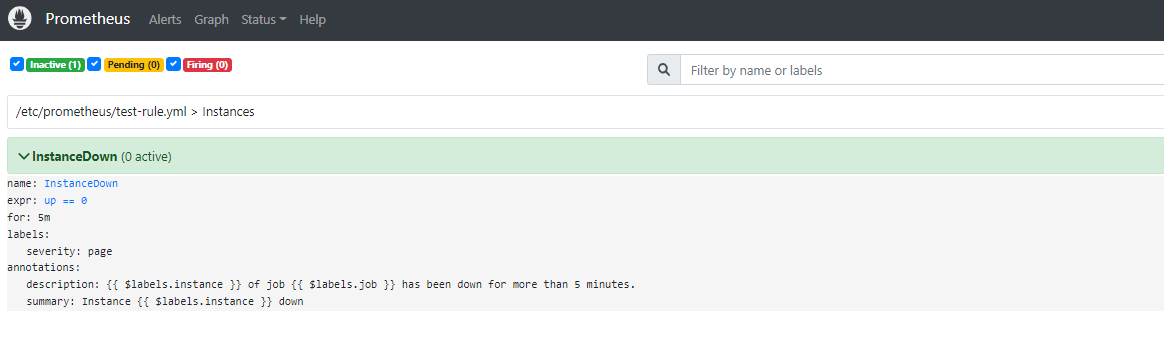
通过以上三个页面就可以判断规则已经生效,不过需要提前说明的是由于上面设置的告警规则中的告警条件为up == 0,意思就是当全部Prometheus监控的应用健康状态都为0 不健康状态时才会触发告警,但是又因为上面Prometheus配置文件中设置了监控Prometheus自身,而Prometheus正常运行时指标up的值至少为1,即 up > 0,所以告警状态从始至终都为没有触发告警的inactive状态
{kind=link}
{kind=link}
 微信
微信
 支付宝
支付宝